Intra- and interobserver reliability of gray scale/dynamic range evaluation of ultrasonography using a standardized phantom
Article information

Abstract
Purpose:
To evaluate intra- and interobserver reliability of the gray scale/dynamic range of the phantom image evaluation of ultrasonography using a standardized phantom, and to assess the effect of interactive education on the reliability.
Methods:
Three radiologists (a resident, and two board-certified radiologists with 2 and 7 years of experience in evaluating ultrasound phantom images) performed the gray scale/dynamic range test for an ultrasound machine using a standardized phantom. They scored the number of visible cylindrical structures of varying degrees of brightness and made a ‘pass or fail’ decision. First, they scored 49 phantom images twice from a 2010 survey with limited knowledge of phantom images. After this, the radiologists underwent two hours of interactive education for the phantom images and scored another 91 phantom images from a 2011 survey twice. Intra- and interobserver reliability before and after the interactive education session were analyzed using K analyses.
Results:
Before education, the K-value for intraobserver reliability for the radiologist with 7 years of experience, 2 years of experience, and the resident was 0.386, 0.469, and 0.465, respectively. After education, the K-values were improved (0.823, 0.611, and 0.711, respectively). For interobserver reliability, the K-value was also better after the education for the 3 participants (0.067, 0.002, and 0.547 before education; 0.635, 0.667, and 0.616 after education, respectively).
Conclusion:
The intra- and interobserver reliability of the gray scale/dynamic range was fair to substantial. Interactive education can improve reliability. For more reliable results, double- checking of phantom images by multiple reviewers is recommended.
Introduction
In the modern era of medicine, diagnostic imaging has become a crucial tool in correct diagnosis, which underpins appropriate treatment. Quality assurance (QA) of medical imaging is of paramount importance.
In Korea, QA for computed tomography (CT), magnetic resonance imaging (MRI), and mammography has been required by law since 2004. Accreditation programs for these imaging modalities are run by the Korean government, and QA testing is performed by the Korean Institute for Accreditation of Medical Imaging under the direction of the Ministry of Health and Welfare [1-3]. However, QA for ultrasonography (US) examinations has not yet been legislated, reflecting the diversity of roles and performance of US devices used in clinical practice and the lack of iodizing radiation. However, in the United States, some scientific bodies have formulated recommendations for US QA [4-6]. The Korean government is currently formulating additional regulations of medical imaging modalities including US.
In Korea, US screening of the liver for hepatocellular carcinoma (HCC) is a part of the National Cancer Screening Program run by the National Cancer Control Institute, which is a part of the National Cancer Center. This program has included surveys regarding QA of US [7-9]. In these surveys, six test items were assessed for phantom image evaluation (dead zone, vertical and horizontal measurement, axial and lateral resolution, sensitivity, gray scale/dynamic range) [7,8]. Among them, gray scale/dynamic range was the most common cause of the failure of phantom image evaluation [7-9]. However, the assessment of gray scale/dynamic range is subjective and might be influenced by the experience and inclination of reviewers. Therefore, for legal regulation, the reliability of subjective items should be validated.
We designed a study to evaluate the intra- and interobserver reliability of a gray scale/dynamic range test using a standardized US phantom. The aims of this study were to verify the intra- and interobserver reliability of the gray scale/dynamic range test in reviewers with different experience levels, and to determine the influence of education sessions on the reliability.
Materials and Methods
Institutional Review Board and Institutional Animal Care and Use Committee approvals were not required because this study did not use any human or animal data.
Acquisition of Phantom Images
Phantom images were recruited as part of a nationwide survey in Korea for the investigation of the quality of US scanners for the screening of HCC in high-risk patients. Forty-nine phantom images from the 2010 survey and 91 phantom images from the 2011 survey were obtained. All of the phantom images were digital images, including Digital Imaging and Communications in Medicine (DICOM) and JPEG file types; no film or thermal paper images were evaluated. An ATS 539 multipurpose phantom (ATS Laboratories, Bridgeport, CT, USA) was used because this phantom is recommended as the standard phantom for QA of US for abdominal imaging by the Korean Society of Radiology and the Korean Society of Ultrasound in Medicine [7-9]. This phantom has also been adopted in several studies as a test phantom [10,11]. The phantom is made of rubber-based tissue-mimicking material that matches the acoustic properties of human tissue and provides test structures (Fig. 1). Research assistants, who were researchers of the Korean Institute for Accreditation of Medical Imaging, transported a standard phantom to medical institutions and obtained the phantom images. All of the phantom images were obtained with a 3.0-5.0 MHz curved-array probe and software settings for abdominal ultrasound, using the test methods recommended by the manufacturer’s manual and the American Association of the Physicist in Medicine (AAPM) guideline [5,12]. The scanning of the phantom was done by the research assistants in the presence of the physician on site.
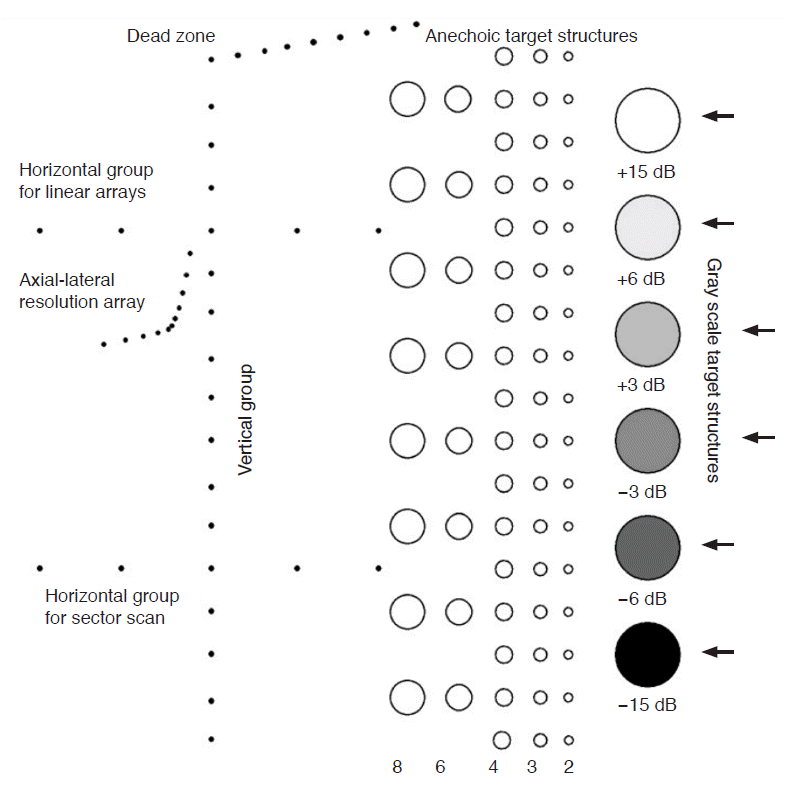
The six test items evaluated were the dead zone, vertical and horizontal measurement, axial and lateral resolution, sensitivity, and gray scale/dynamic ranges. Among them, we assessed the reliability of the gray scale/dynamic range, which is the test item for evaluating the contrast of the images, and which uses the amplitude of the received echoes to vary the degree of brightness in US images. Six cylindrical targets with varying degrees of brightness were visible in the US images. The contrast values of six targets compared to the background material were +15, +6, +3, -3, -6, and -15 dB.
First Review Round
US phantom images were independently reviewed by three radiologists. Two were board-certified radiologists with 7 years of experience (reviewer 1) and 2 years of experience (reviewer 2) evaluating US phantom images. The third member was a junior resident who had 6 months experience in abdominal US (reviewer 3). The process used to evaluate the phantom images is summarized in Fig. 2. Each reviewer initially evaluated 49 phantom images from the 2010 survey with brief knowledge for judgment of the gray scale/ dynamic range test. All of the images were reviewed on an M-view picture archiving and communications system (PACS) workstation monitor (Infinitt, Seoul, Korea). The number of cylindrical targets that appeared as discrete round structures through more than 180° were counted. The ‘pass or fail’ cutoff value was more than four cylindrical structures visible as round structures [8] (Figs. 3, 4). The first review consisted of two review sessions to calculate interobserver reliability, with two reviews of the phantom images. To avoid recall bias, the second review session was performed 2 weeks after the first session.
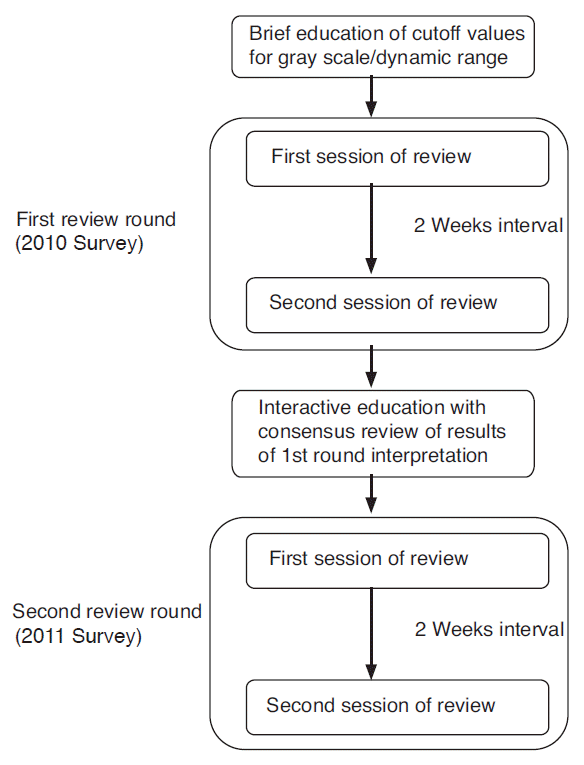
Flow chart of the review process.
The review process consists of two review rounds and one interactive education session between rounds. Each round consists of two review sessions separated from each other by more than two weeks. The first review round was performed with 49 phantom images from the 2010 survey and the second round with 91 phantom images from the 2011 survey.

An example of a "passed" phantom image of the gray scale/dynamic range.
Four round structures are clearly visible over 180°. The contrast values of these targets are +15, +6, +3, -3, -6, and -15 compared to the background. In this case, four targets are clearly visible as round structures (arrows) and two structures are not visible as round over 180° (arrowheads).

An example of a "failed" phantom image of the gray scale/dynamic range.
Only three round structures are clearly visible over 180°. The contrast values of these targets are +15, +6, +3, -3, -6, and -15 compared to the background. In this case, only three targets are clearly visible as round structures (arrows) and three structures are not visible as round over 180° (arrowheads).
Interactive Education
After the first review round, the three reviewers received two hours of interactive education concerning phantom image evaluation. In this education session, they evaluated 49 phantom images from the 2010 survey together and reached consensus concerning the number of round structures. This education session was supervised by the most experienced reviewer (reviewer 1).
Second Review Round
After the interactive education, the three reviewers independently scored another set of 91 phantom images from the 2011 survey. The review also consisted of two review sessions with an intervening 2-week interval. The reviewers again recorded the number of visible round structures and passed or failed results according to the above cutoff value.
Statistical Analyses
Statistical analyses were performed using MedCac ver. 9.2 (MedCalc Software, Mariakerke, Belgium). Inter- and intraobserver reliability before and after the interactive education were analyzed using K statistics with a weighted K-value for the number of visible round structures (0-6 cylindrical structures) and K-value for pass/fail. Interobserver reliability was calculated from the second set of data of each review round. Strengths of the intra- and interobserver reliability were determined using criteria detailed previously [13]. The following classification was used for the level of agreement by K-value: <0.20, poor agreement; 0.21-0.40, fair agreement; 0.41-0.60, moderate agreement; 0.61-0.80, good agreement; and 0.81-1.00, very good agreement. In addition, intra- and interobserver agreement rates (%) were also calculated in terms of passing or failing. Comparison of pass rates (%) of the two sets of interpretation was performed using Fisher exact test. Agreement rates were calculated because K-values can be distorted due to the prevalence effect [14,15]. A P<0.05 indicated statistical significance.
Results
Intraobserver Reliability
After interactive education, intraobserver reliability was improved for reviewers 1 and 3, but not for reviewer 2 (Table 1). On the other hand, intraobserver reliability (K-values) for passing/failing improved in all of the reviewers (Table 2). In addition, Fisher exact test of the intraobserver agreement rate (%) for passing/failing showed an improved reliability rate in reviewer 1, but no significant change in reviewers 2 or 3 (Table 3).
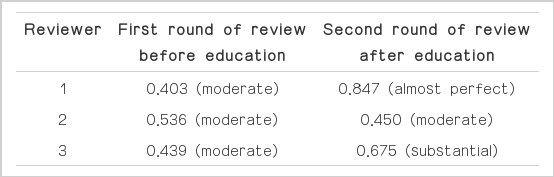
Intraobserver reliability (weighted k-values) for the number of round structures

Intraobserver reliability (k-values) for pass/fail

Intraobserver reliability (k-values) for pass/fail
Interobserver Reliability
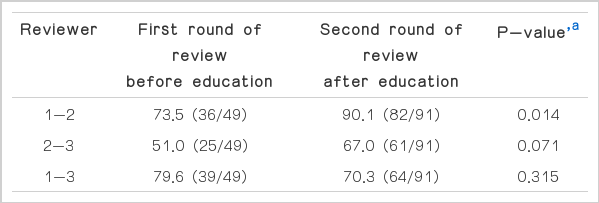
After interactive education, the interobserver reliability for scores improved all reviewer-pairs (Table 4). The interobserver reliability for passing/failing was also improved in all of the reviewer-pairs (Table 5). In addition, Fisher exact test of the interobserver reliability rate (%) for passing/failing showed an improved reliability rate between the reviewer 1-2 pair, but no significant change in the reviewer 2-3 and 1-3 pairs (Table 6).

Intraobserver reliability (k-values) for pass/fail

Intraobserver reliability (k-values) for pass/fail
Intraobserver reliability (k-values) for pass/fail
Discussion
US screening of HCC is recommended by many scientific bodies worldwide [16-19]. The American Association for the Study of Liver Disease has stressed the importance of QA of screening US examinations for HCC [17]. In Korea, legal regulations concerning QA of medical imaging are limited to CT, MRI, and mammography. However, the need for QA of other imaging modalities is real and becoming more important; US, fluoroscopy, and positron emission tomography are expected to be included in the Korean regulatory framework soon. Surveys of QA of US have been done for several years in Korea as a prelude to legislation [7-9,20].
The QA of medical imaging consists of three components: personnel evaluation (assessment of personnel performing imaging studies), phantom image evaluation (assessment of the performance of the hardware and software of imaging devices), and clinical image evaluation (testing of imaging protocols). Among these, we concentrated on the phantom image evaluation because the failure rate was relatively higher compared to clinical image evaluation. In the analyses of the 3-year survey from 2008 to 2010, the failure rate of phantom image evaluation increased from 20.9% to 24.5%, and that of clinical image evaluation increased from 5.5% to 9.5% [7]. The failure rate of clinical imaging evaluation can also be reduced by the education of physicians. However, improving the performance of phantom image evaluation is challenging because it is related to the hardware itself and often requires a hardware upgrade. The most common cause of failure in phantom image evaluation was the gray scale/dynamic range, which represented 42.6% of failures overall [7]. However, assessment of the gray scale/dynamic range by visual inspection can be very subjective, and intraobserver and interobserver reliability should be validated for test items used for legal regulation.
Due to the subjective nature of visual inspection, computerized automated evaluation of parameters of US images has been considered [10,11,21-24]. A relatively high subjectivity of visual inspection has been reported [25]. However, in the real world, many US units use thermal paper or film as the output method, negating automatic computerized evaluation. The reality is that visual inspection needs to be more reliable. The present study is useful in this situation.
In this study, intraobserver reliability after interactive education was moderate to almost perfect, particularly the pass/fail reliability. Intraobserver reliability was also improved for both the number of round structures and the pass/fail decision after the interactive education, and intraobserver agreement rates were quite high after interactive education (>85% in all reviewers), although statistically significant improvement was evident only in reviewer 1. Therefore, especially after proper education, intraobserver reliability was quite good.
Interobserver reliability for the number of round structures after education was fair to substantial. This result is somewhat disappointing, especially given the declined performance in reviewer 3 after education. Interobserver reliability for passing/failing was good and improved in all of the reviewers after education. However, the interobserver agreement rate was 67.0% to 90.1%, and significant improvement was observed only in the pair of reviewer 1-2. This result was poorer than the level of interobserver reliability of a previous study [8] that reported interobserver reliability of two reviewers who were experienced abdominal radiologists with more than 5 years of experience in evaluating US phantom images for gray scale/dynamic range (K-value of 0.652 for the number of round structures and 0.969 for pass/fail, interobserver agreement rate 98.6%).
The cause of poorer interobserver agreement of our study might have been the relative inexperience of the reviewers, especially reviewer 3, who was a senior resident. The outcomes between the reviewer 2-3 and 1-3 pairs were inferior in both interobserver reliability (weighted K-values) for scores after the education sessions and the interobserver agreement rate (%) for the pass/fail decision. The level of experience may influence interobserver reliability even after interactive education. In addition, before education, reviewer 2 had standards that were too generous and interobserver agreement was very low in the reviewer pairs including reviewer 2. However, this tendency was corrected after interactive education, and this provides evidence for the necessity of proper education for reviewers to attain reliable results.
Our results are not sufficient for testing concerning legal regulation, and therefore, reviewers for legal regulation should be experienced radiologists and appropriate education must be performed. Furthermore, a double-check system is mandatory to reduce personal errors. For CT, MRI, and mammography, two to five reviewers need to be involved in QA testing for legal regulation. This system should be adopted for the QA of US when legal regulation is legislated.
Our study has some limitations. First, only three reviewers participated. For the accreditation system and legal regulations, more robust results are needed. Studies involving multiple, experienced reviewers must be performed before legislation is formulated and implemented. Second, we analyzed various US scanners and probes with a single, standard phantom. The optimal phantoms for individual US units can vary. However, a previous study reported that the various combinations of scanners and probes do not significantly alter the results of phantom images [26]. Third, we only evaluated digital images. US units with analogue outputs, such as films or thermal papers, still comprise the majority of units in use. As the image quality of these analogue images is generally poorer than those of digital images, reliability could be inferior to the present results. For legal regulation, a study with a larger number of cases of analogue images with multiple, experienced reviewers will be necessary. Fourth, the data from the 2010 survey and 2011 survey might be of varying quality and this could make a difference in the reliability. However, the failure rates of the 2010 and 2011 surveys for the phantom image evaluation were similar according to a government report. Fifth, this study was performed in two months, and reviewer 3 (a junior resident) experienced many US cases during that period. Therefore, the performance of reviewer 3 could have improved for the second round of review compared to the first round, and this could have influenced the results of this study. However, the tendency of the results from other reviewers was robust, and the impact of the resident’s increasing experience was probably not substantial.
In conclusion, the intraobserver reliability of the results of the gray scale/dynamic range was good, especially after the interactive education session. The interobserver reliability could be improved by education. Whether this approach will yield results necessary for legal regulation is unclear. Therefore, the involvement of experienced reviewers, proper education, and a double check system for accreditation are mandatory.
Notes
No potential conflict of interest relevant to this article was reported.
Acknowledgements
This study was supported in part by the Phillips Research Fund of the Korean Society of Ultrasound in Medicine. This study was also partly supported by a grant from the National Cancer Control Institute of the National Cancer Center of Korea and by the Ministry of Health, Welfare and Family Affairs of Korea. This study was performed with the help of the Korean Society of Radiology and the Korean Institute for Accreditation of Medical Imaging.