


Feasibility of a deep learning artificial intelligence model for the diagnosis of pediatric ileocolic intussusception with grayscale ultrasonography
-
Se Woo Kim1,2
 , Jung-Eun Cheon2,3, Young Hun Choi3, Jae-Yeon Hwang4, Su-Mi Shin5, Yeon Jin Cho3, Seunghyun Lee3, Seul Bi Lee3
, Jung-Eun Cheon2,3, Young Hun Choi3, Jae-Yeon Hwang4, Su-Mi Shin5, Yeon Jin Cho3, Seunghyun Lee3, Seul Bi Lee3
- Received August 7, 2023 Revised October 6, 2023 Accepted October 10, 2023
- ABSTRACT
-
- Purpose
- This study explored the feasibility of utilizing a deep learning artificial intelligence (AI) model to detect ileocolic intussusception on grayscale ultrasound images.
- Methods
- This retrospective observational study incorporated ultrasound images of children who underwent emergency ultrasonography for suspected ileocolic intussusception. After excluding video clips, Doppler images, and annotated images, 40,765 images from two tertiary hospitals were included (positive-to-negative ratio: hospital A, 2,775:35,373; hospital B, 140:2,477). Images from hospital A were split into a training set, a tuning set, and an internal test set (ITS) at a ratio of 7:1.5:1.5. Images from hospital B comprised an external test set (ETS). For each image indicating intussusception, two radiologists provided a bounding box as the ground-truth label. If intussusception was suspected in the input image, the model generated a bounding box with a confidence score (0-1) at the estimated lesion location. Average precision (AP) was used to evaluate overall model performance. The performance of practical thresholds for the model-generated confidence score, as determined from the ITS, was verified using the ETS.
- Results
- The AP values for the ITS and ETS were 0.952 and 0.936, respectively. Two confidence thresholds, CTopt and CTprecision, were set at 0.557 and 0.790, respectively. For the ETS, the perimage precision and recall were 95.7% and 80.0% with CTopt, and 98.4% and 44.3% with CTprecision. For per-patient diagnosis, the sensitivity and specificity were 100.0% and 97.1% with CTopt, and 100.0% and 99.0% with CTprecision. The average number of false positives per patient was 0.04 with CTopt and 0.01 for CTprecision.
- Conclusion
- The feasibility of using an AI model to diagnose ileocolic intussusception on ultrasonography was demonstrated. However, further study involving bias-free data is warranted for robust clinical validation.
- Key point
-
Key pointA deep learning model based on the YOLOv5 architecture, with a speed of several tens of frames per second, successfully diagnosed intussusception on grayscale ultrasound images with acceptable accuracy. The applicability of this deep learning model in the development of real-time ultrasound diagnostic assistance software for point-of-care ultrasound requires further verification.
- Graphic Abstract
- Graphic Abstract
- Introduction
- Introduction
Intussusception, defined as the invagination of a bowel segment (intussusceptum) into the distal bowel (intussuscipiens), is a leading cause of acute abdominal pain and intestinal obstruction in young children, particularly those between the ages of 3 months and 3 years [1-3]. Approximately 90% of pediatric intussusception cases are idiopathic and ileocolic in nature [1]. Ileocolic intussusception is a pediatric emergency that can lead to bowel ischemia, necrosis, and perforation if left untreated [1,3]. However, the classic clinical triad of ileocolic intussusception (colicky abdominal pain, vomiting, and bloody stools) is exhibited by only 7.5% to 40% of children at initial presentation [1,3]. Furthermore, diagnosing ileocolic intussusception can be challenging due to the substantial overlap in clinical symptoms with other conditions causing abdominal pain or vomiting, such as viral gastroenteritis. This overlap applies to the vast majority of cases and necessitates diagnostic imaging [1,3].Since its initial documentation in 1793, the diagnosis and treatment of ileocolic intussusception have undergone several paradigm shifts [4]. At present, ultrasonography is the favored diagnostic test for ileocolic intussusception due to its near-perfect sensitivity and specificity, as well as the lack of radiation risk [5-8]. Similarly, the preferred treatment method is non-operative reduction via hydrostatic or air enema, unless signs of peritoneal irritation that contraindicate an enema are present [1,3,5,8].The time from symptom onset to the initiation of treatment is the most important prognostic factor for patient outcomes [9-13]. Consequently, multiple methods are being developed to expedite the diagnostic process. One such approach involves the use of point-of-care ultrasonography (POCUS) by non-radiologist physicians or radiographers. However, the diagnostic reliability of POCUS when used by untrained physicians is a major concern [14-18]. A recent meta-analysis revealed that the diagnostic accuracy for intussusception was comparable between POCUS and radiologist-performed ultrasound (RADUS), with an area under the receiver operating characteristic (ROC) curve of 0.95 versus 1.00, respectively (P=0.128) [16]. In a study comparing non-radiologist certified sonologists and radiologists, POCUS demonstrated diagnostic accuracy that was not inferior to that of RADUS, with accuracy rates (95% confidence intervals) of 97.7% (94.9% to 99.0%) and 99.3% (94.7% to 99.2%), respectively [17]. However, a comparative study between experienced and novice sonologists found that the sensitivity and specificity of novice sonologists were lower than those of their experienced counterparts, at 80.0% and 50.3% versus 100.0% and 71.4%, respectively. Furthermore, the proportion of inconclusive cases was higher among novice sonologists, at 30.7% compared to 14.0% among experienced sonologists [18].Recent advancements in artificial intelligence (AI) have led to the development of several deep learning-based clinical decision support systems, which have then been used in various medical fields. Several of these models have demonstrated good performance in diagnosing intussusception based on plain abdominal radiographs [19,20]. However, to these authors’ knowledge, no prior reports have been published on the feasibility of AI models for diagnosing intussusception using ultrasound images. The slow progress in developing deep learning-based diagnostic models for ultrasound compared to other imaging modalities may be attributed to two primary factors. The first is technical difficulty; since ultrasonography is a real-time imaging modality, the model must be capable of processing images at a rate of several tens of frames per second. The second is inherent bias in training data. This stems from a high degree of operator-dependency, as operator decisions are necessary at all stages of image acquisition, such as determining which area to scan and which of the scanned images to save [21,22]. To overcome these challenges, a fast, single-stage object detection architecture capable of real-time image processing and bias-free training data is needed.The purpose of this study was to explore the feasibility of utilizing a deep learning AI model, based on the YOLOv5 single-stage object detection architecture, for the detection of ileocolic intussusception on grayscale ultrasound images.
- Materials and Methods
- Materials and Methods
- Compliance with Ethical Standards
- Compliance with Ethical Standards
This retrospective observational study received approval from the institutional review boards (IRBs) of two participating institutions: hospital A (IRB No. 2112-076-1282) and hospital B (IRB No. 05-2022-230). Due to the retrospective nature of the study, the IRBs waived the requirement for informed consent.- Study Population and Data Curation
- Study Population and Data Curation
Fig. 1 summarizes the enrollment of study participants and the process of data curation. This study included pediatric patients (those aged 18 years or younger) who visited the emergency department and underwent an ultrasound examination for suspected ileocolic intussusception. The reference standard for the diagnosis of ileocolic intussusception was a combination of ultrasound image interpretation by attending radiologists, fluoroscopic findings from subsequent air enema, and operative records in cases of open reduction. Consequently, a total of 2,438 children (636 with intussusception and 1,802 without) who visited hospital A between January 2013 and December 2021, along with 124 children (20 with intussusception and 104 without) who visited hospital B between October 2021 and December 2021, were consecutively enrolled.The study incorporated only the grayscale ultrasound images of the participating children, irrespective of whether the bowel was present or absent. Any video clips, color Doppler images, or images containing annotations (such as text annotations, arrows, or size measurements) were excluded. Consequently, a total of 40,765 images (38,148 from hospital A and 2,617 from hospital B) were collected.The development dataset included 2,775 images featuring intussusception (1,098 convex, 831 linear trapezoidal, and 846 linear images) and 35,373 images without intussusception (12,254 convex, 11,648 linear trapezoidal, and 11,471 linear images), all collected from hospital A. This development dataset was randomly split into a training set, a tuning set, and an internal test set (ITS) in a ratio of 7:1.5:1.5. This division was performed at the image level and was stratified based on the label (either intussusception-positive or intussusception-negative) and the type of ultrasound transducer used (convex, linear, or linear trapezoidal). The external test set (ETS) consisted of 2,617 images from hospital B, which included 140 intussusception-positive and 2,477 intussusception-negative images.Detailed information about the machines and transducers used for this study can be found in the Supplementary Table 1. The images utilized in this research were obtained by 637 physicians, including residents, fellows, and staff doctors from the radiology departments of two hospitals. These doctors had varying levels of experience in pediatric ultrasonography, ranging from 1 to 32 years. The images were captured using 12 different ultrasound machines, sourced from seven unique manufacturers.- Reference Standard Annotation
- Reference Standard Annotation
All images were subjected to ground-truth labeling using open-source web-based annotation software (LabelMe) [23,24]. For images displaying clear signs of intussusception (both axially scanned images with the "target sign" and longitudinally or obliquely scanned images with the "pseudokidney sign"), the smallest possible rectangular region of interest (ROI) that encompassed the entire lesion was delineated by two radiologists (S.W.K. and Y.H.C., who have 6 years and 18 years of experience, respectively, in the ultrasound diagnosis of intussusception). No distinction was made between intussusceptions with and without a leading point. For images that did not show intussusception, or when intussusception was suspected but a portion of the image either was obscured by artifacts or fell outside the field of view, no ROI was drawn. These images were classified as negative for intussusception.- Deep Learning Model Development
- Deep Learning Model Development
Fig. 2 summarizes the architecture and training process of the deep learning model used, which was based on the YOLO architecture, specifically YOLOv5, which is the fifth iteration of the widely recognized single-stage object detector [25,26]. Unlike traditional two-stage detection architectures such as RCNN or SPPNet, YOLO integrates region proposal, feature extraction, classification, and bounding box regression into a single stage. This integration facilitates real-time object detection [25,27].The YOLO model suggests predictions in the form of a bounding box, which includes the x- and y-coordinates of the box center, the box width, and the box height, as well as a class confidence score ranging from 0 to 1. This score represents the model’s confidence that the object within the box belongs to a specific class. Each input image can have zero, one, or multiple bounding boxes. Prior to training, the model was initialized with pre-trained weights obtained from the official YOLO GitHub (YOLOv5x) [26]. Training was conducted for a maximum of 300 epochs using the training and tuning sets, employing the default learning hyperparameters for fine-tuning [26]. Weights that produced the least loss in the tuning set were considered optimal and established as the final weights for the model. Once training with the training and tuning sets was completed, the model generated predictions for images in the ITS and ETS.- Performance Metrics and Statistical Analysis
- Performance Metrics and Statistical Analysis
Metrics that are widely used for evaluating the performance of object detection algorithms, including precision, recall, and average precision, were computed [28]. In the context of object detection tasks, several key terms can be defined as follows: a true positive (TP) refers to the correct detection of a ground-truth bounding box, a false positive (FP) refers to the incorrect detection of a non-existent object or the misplaced detection of an existing object, and a false negative (FN) refers to a ground-truth bounding box that is not detected. Precision and recall are respectively calculated as TP/(TP+FP) and TP/(TP+FN), which correspond to the positive predictive value and sensitivity, respectively. Average precision is defined as the area under the curve (AUC) of the precision-recall (PR) curve. For object detection algorithms that encompass multiple classes, the mean average precision at a specific intersection-over-union (IOU) threshold t (mAPt) is commonly used to estimate the overall performance of the model. Because the model task in the present study was single-class object detection, the overall model performance was evaluated by calculating the AUCs of the PR curves in the ITS and ETS at an IOU threshold of 0.5, which were equivalent to mAP0.5.The optimal threshold values for the model-generated confidence scores were ascertained from the ITS. Two confidence thresholds (CTopt and CTprecision) were established based on the F1 score, which represents the harmonic mean of precision and recall, as well as the required degree of precision. Of these two thresholds, the former resulted in the maximum F1 score, while the latter produced the maximum F1 score at a precision exceeding 98.0%. The same confidence thresholds were applied to the ITS and ETS, and the precision and recall were computed.Within the ETS, the diagnostic performance per patient was assessed based on the following criteria. (1) For patients with intussusception, a case was classified as a TP if the model generated at least one correct prediction with a confidence score surpassing predetermined thresholds (CTopt or CTprecision). (2) For patients without intussusception, a case was classified as a TN if the model did not make any predictions that exceeded the predetermined confidence threshold across all images. In contrast, if any prediction was made, the case was classified as an FP. The per-patient diagnostic performance of the model was evaluated using ROC curve analysis. Additionally, free-response ROC (FROC) curve analysis and alternative free-response ROC (AFROC) curve analysis were conducted for the ETS.
- Results
- Results
- Determination of Optimal Confidence Thresholds
- Determination of Optimal Confidence Thresholds
For the ITS, the confidence score yielding the maximum F1 value (0.925) was 0.557; this score was denoted as CTopt. Another confidence threshold, referred to as CTprecision, was established at 0.790 and yielded an F1 score of 0.771. The precision and recall of this model within the ITS were 94.5% (377/399) and 90.6% (377/416), respectively, when using CTopt. When using CTprecision, these values were 98.1% (264/269) and 63.5% (264/416), respectively.- Per-lesion and Per-patient Diagnostic Performance of Confidence Thresholds in the ETS
- Per-lesion and Per-patient Diagnostic Performance of Confidence Thresholds in the ETS
Within the ETS, the precision and recall of the present model were 95.7% (112/117) and 80.0% (112/140), respectively, when CTopt was utilized. With CTprecision, these values were 98.4% (62/63) and 44.3% (62/140), respectively. Fig. 4 illustrates representative cases of FPs and FNs.In the per-patient analysis, the sensitivity and specificity were determined to be 100.0% (20/20) and 97.1% (101/104), respectively, with CTopt. When using CTprecision, these respective values were 100.0% (20/20) and 99.0% (103/104). Fig. 5 depicts the ROC, FROC, and AFROC curves for the per-patient diagnosis of ileocolic intussusception in the ETS. The average number of FPs per patient when using CTopt and CTprecision were 0.04 (5/124) and 0.01 (1/124), respectively. The areas under the ROC curve and the AFROC curve for the ETS were 0.999 and 0.940, respectively. Table 2 summarizes the key results of this study.
Table 1 summarizes the baseline characteristics of the study population. No significant difference was observed in the age or sex distribution between the development dataset and the ETS. However, these datasets differed significantly in the proportions of patients and images with ileocecal intussusception (patients: 26.1% [636 of 2,438] vs. 16.1% [20 of 124]; images: 7.3% [2,774 of 38,148] vs. 5.3% [140 of 2,617], respectively). Fig. 3 depicts the PR curve and the F1 score confidence curve for the ITS and ETS. The overall performance of the model was excellent for both ITS and ETS, with mAP0.5 values of 0.952 and 0.936, respectively.
- Discussion
- Discussion
In the present study, a YOLOv5-based deep learning AI model exhibited excellent overall performance for the detection of ileocolic intussusception, with mAP0.5 values ranging from 0.936 to 0.952. The two optimal cut-off thresholds, CTopt and CTprecision, demonstrated high precision (94.5%-98.1%) and recall (63.5%-90.6%) within the ITS. When applied to the ETS, these thresholds retained high precision (95.7%-98.4%) but exhibited lower recall (44.3%-80.0%). Nevertheless, the sensitivity and specificity for per-patient diagnosis were excellent (100.0% and 97.1%-99.0%, respectively) when the same thresholds were used.In the per-patient analysis, a case was classified as a TP if at least one prediction was made with confidence and IOUactual-predicted above the established thresholds. This assumption indicates that even if TP detection only applies to some (that is, one or more) of several ileocolic intussusception images of a patient, the case-level diagnosis is still considered a TP. This results in inflated per-patient sensitivity (100.0%) when compared to the per-lesion sensitivity (44.3% to 90.6%). Similarly, as more images are included in the examination, per-patient specificity would be expected to decrease, since the model’s chance of detecting FP would likely increase. Therefore, maintaining the high precision of the model is anticipated to improve per-patient diagnostic accuracy. This was confirmed by the enhanced per-patient specificity and preserved per-patient sensitivity of CTprecision (99.0% and 100.0%, respectively) compared with those of CTopt (97.1% and 100.0%, respectively). Given that per-patient factors such as the number of images and the ratio of lesion-positive to lesion-negative images could influence the per-patient diagnostic performance of the model, FROC and AFROC curve analyses were conducted. In the FROC analysis, the average numbers of FPs per patient determined using CTopt and CTprecision were acceptable (0.04 and 0.01, respectively). Furthermore, the area under the AFROC curve for the ETS was excellent (0.940).A key strength of this study lies in its generalizability. Despite the participation of only two centers, the training and test data included images acquired by more than 600 radiologists, who had levels of experience ranging from 1 to 32 years. These images were captured using 12 different ultrasound machines from seven distinct manufacturers. In the development of a deep learning model, addressing the so-called overfitting issue is crucial to ensure broad applicability of the model [29]. Further research, ideally involving data from multiple institutions, would be beneficial in further reducing model overfitting.Two prior studies utilizing plain radiographs reported per-patient sensitivity and specificity values of 65.1%-94.7% and 48.5%-96.0%, respectively [19,20]. These figures are somewhat lower than those observed in the present investigation. The superior diagnostic accuracy per patient in this study can be ascribed to the differences in the imaging modality used. Plain radiographs possess inherent limitations that interfere with the accurate diagnosis of ileocolic intussusception. Consequently, the authors of the two preceding studies also contended that the clinical utility of their deep learning models resides in their potential to serve as effective screening tools for identifying children who may require further ultrasound examination.Further validation of the model using bias-free data is essential for its future application in clinical practice. In the ultrasound diagnosis of intussusception, the model in this preliminary study replaced only the final step in the sequence of (1) scanning, (2) selecting and storing images, and (3) diagnosing based on the stored images. During a bedside ultrasound examination, the area to be scanned, the images to be saved, and the images to be discarded are all determined based on the operator’s judgment. The performance of the present model in a laboratory setting, where biases due to operator dependency are not corrected, would likely differ substantially from the results when applied in a real-world environment. This inference is supported by the observed difference in model performance between the ITS and ETS, which exhibit significant differences in data composition, such as the ratio of lesion-positive to lesion-negative images. In a follow-up study, these authors plan to validate the model again using bias-free data obtained through a unified scanning protocol that scans a predetermined area and saves all frames as video storage. Considering that modern ultrasound machines generate images at a rate of 10 to 30 frames per second, a 10-minute examination could produce between 6,000 and 18,000 images. In this non-selectively collected dataset, both the numbers of lesion-positive and lesion-negative images, as well as the ratio of lesion-negative to lesion-positive images, are expected to greatly exceed those of the current training and test datasets. Furthermore, the quality of each image is likely to be lower than the images used in the present study. A larger number of input images would necessitate greater precision to limit the number of FPs, while the lower quality of each image would require higher recall to avoid FNs. At present, determining the optimal balance between precision and recall is challenging, and further research is needed.The YOLO architecture was selected over other deep learning architectures due to its superior speed. The ultimate objective was to develop a fully integrated real-time ultrasound diagnostic support system. Should this model demonstrate acceptable per-lesion and per-patient diagnostic accuracy in follow-up research, it could eventually be integrated into an ultrasound system. The key to success in this endeavor would be the speed at which lesion detection can be performed without delay, ideally at a rate not slower than the ultrasound frame rate. Among the available object detection architectures, YOLO is the most appropriate for this purpose, as it offers the fastest predictions with sufficient accuracy [27].Notably, the role of radiologists extends far beyond the simple detection of intussusception. Their responsibilities also include the exploration of potential alternative diagnoses, the identification of leading points, and the provision of guidance for management decisions, such as whether to opt for surgical or non-surgical treatment. Consequently, even with the most advanced models currently available or those that may be developed in the future, it is unlikely that radiologists could be entirely replaced. However, as previously noted, the use of POCUS is increasingly being incorporated into clinical practice to reduce the time from symptom onset to diagnosis [9-11]. Therefore, any method that can enhance the diagnostic accuracy and confidence of POCUS could potentially improve patient prognosis and decrease the overall cost of treatment. As such, the present study, serving as a preliminary investigation for the development of a fully integrated ultrasound diagnostic support system, holds the potential to improve the prognosis of children with intussusception.The present study did have certain limitations. First, due to its retrospective nature, the study possessed inherent selection bias. However, patients were enrolled consecutively to minimize this impact. Second, the operator-dependent nature of the ultrasound examination introduced additional bias. Therefore, as previously mentioned, a further prospective study utilizing real-time ultrasound cine images, obtained through a standardized scanning protocol, is necessary to assess the real-world applicability of this AI model without operator dependency. Finally, the inherent interpretability limitation in deep learning, often referred to as the "black box" problem, could also be considered a limitation of this study.In conclusion, a deep learning-based AI model utilizing grayscale ultrasound images demonstrated reasonable diagnostic performance in the detection of ileocolic intussusception. Despite certain limitations, the feasibility of the model was adequately confirmed. However, further research is necessary to reach the ultimate objective of developing a fully integrated ultrasound diagnostic support system.
- NOTES
- NOTES
-
Author Contributions Conceptualization: Kim SW, Cheon JE, Choi YH. Data acquisition: Kim SW, Cheon JE, Choi YH, Hwang JY, Lee S, Lee SB. Data analysis or interpretation: Kim SW, Shin SM. Drafting of the manuscript: Kim SW. Critical revision of the manuscript: Kim SW, Cheon JE, Choi YH, Hwang JY, Shin SM, Lee S, Lee SB. Approval of the final version of the manuscript: all authors.
Jung-Eun Cheon serves as Editor for the Ultrasonography, but has no role in the decision to publish this article. All remaining authors have declared no conflicts of interest.
- ACKNOWLEDGMENTS
- ACKNOWLEDGMENTS
Young Hun Choi received a research grant from the Seoul National University Research and Development Foundation (SNU R&DB Foundation; Research No. 800-20170130).
Supplementary Material
Supplementary Material
usg-23153-Supplementary-Table-1.pdfSupplementary Table 1.
The list of ultrasound machines and transducers used (https://doi.org/10.14366/usg.23153).
Fig. 1.
Patient inclusion and data preparation.
ER, emergency room; US, ultrasonography; Cvx, convex transducer image; Lin, linear transducer image; LinTz, linear transducer image with trapezoidal window; (+), images with intussusception; (-), images without intussusception.

Fig. 2.
Schematic of YOLOv5 architecture and example images.
A. The input image, with a size of N×N, passes through convolutional and fully connected layers. B. Concurrently with (A), the input image is divided into a grid of A×A cells. C. For each grid, the model generates B predictions (bounding boxes with a width of Wi and a height of Hi) centered at a point (Xi, Yi) within the grid. Each grid has C class probabilities (Probj×Prclassi). D. Following the application of non-maximum suppression, the remaining bounding box or boxes are proposed as the final prediction, along with the class probability.
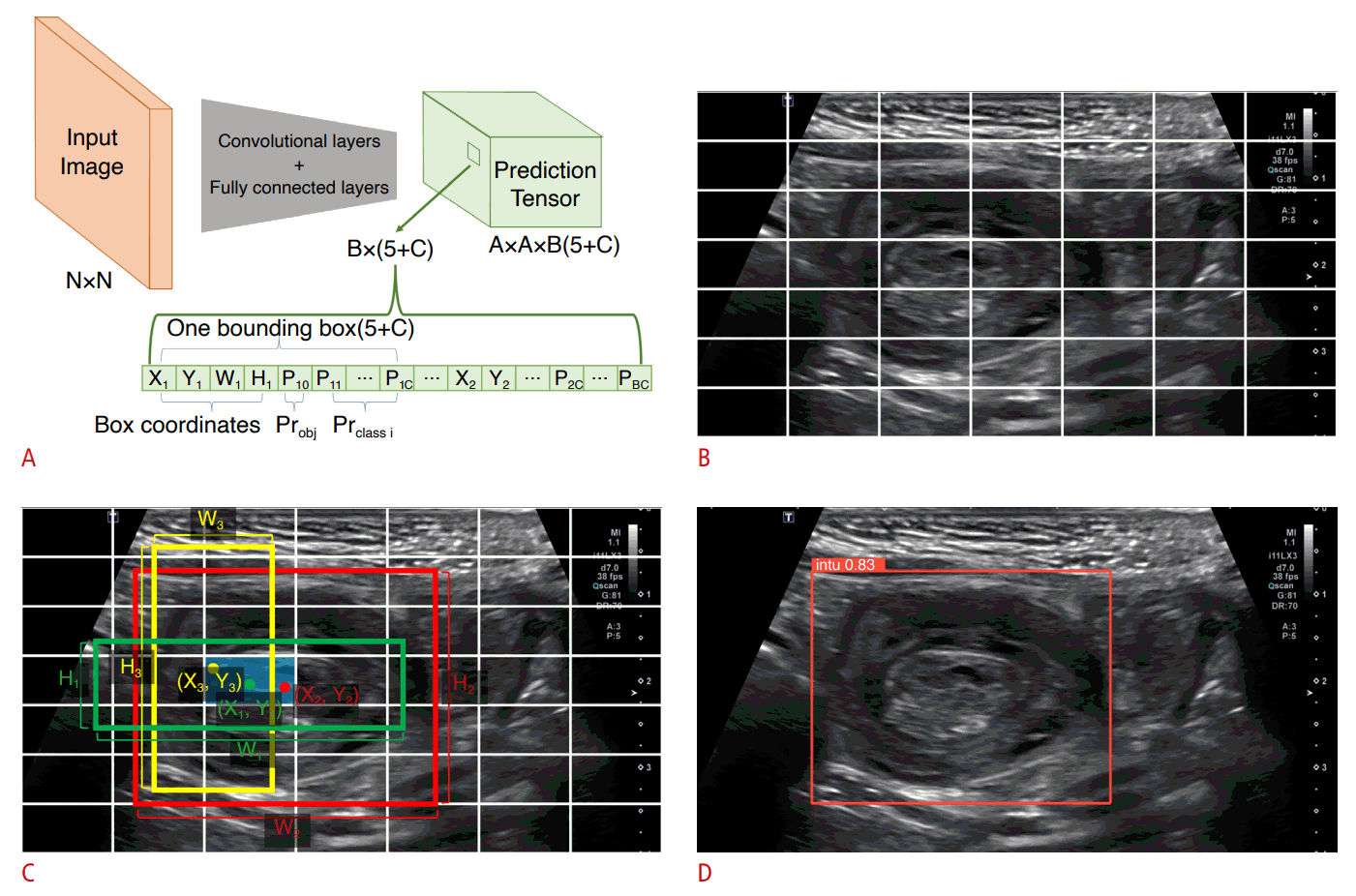
Fig. 3.
Precision-recall (PR) curves and F1 score curves of the model for the internal and external test sets.
A,B. PR curve and F1 score curve for the internal test set are depicted. C,D. PR curve and F1 score curve for the external test set are depicted. AUC, area under the curve; CT, confidence threshold.
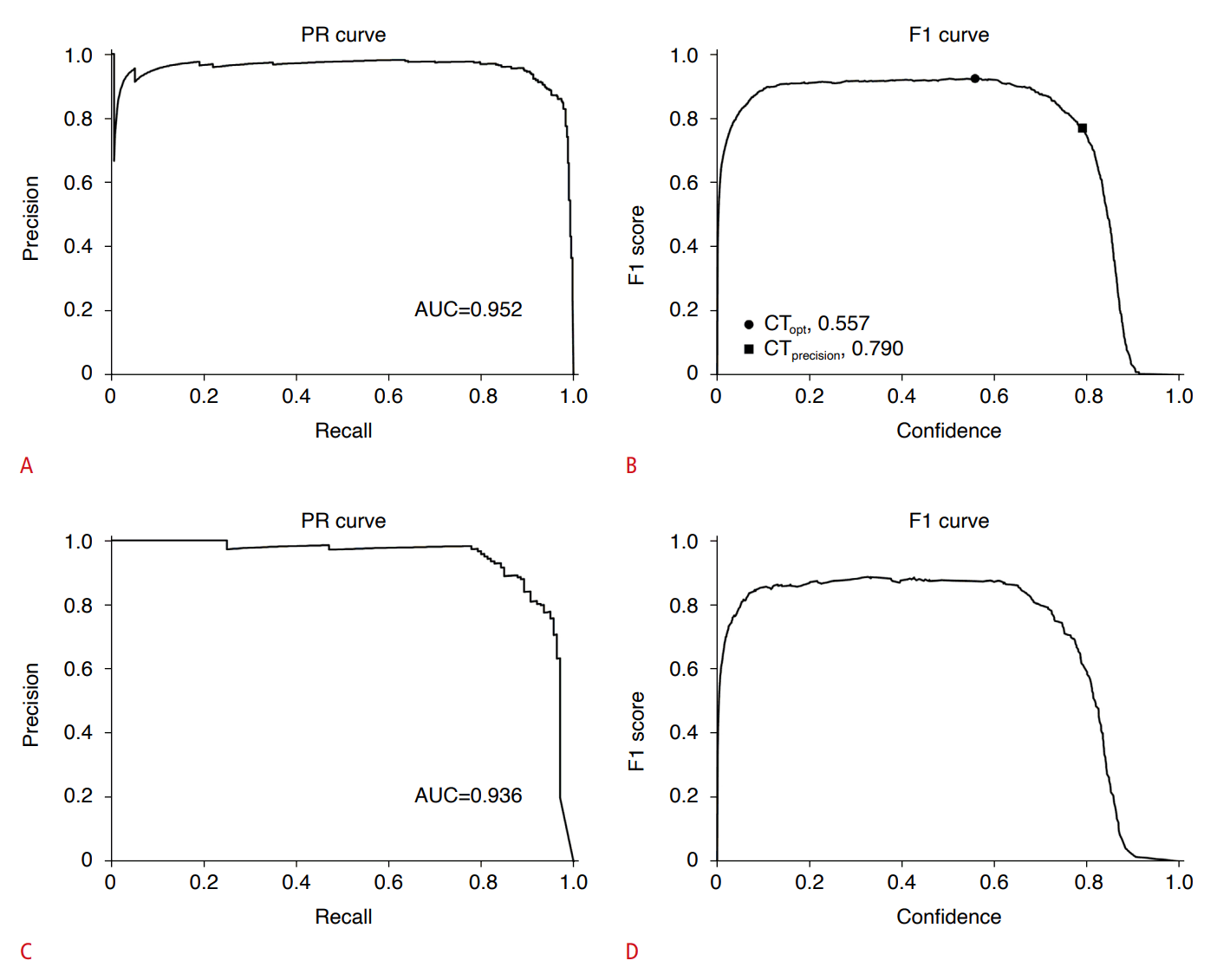
Fig. 4.
Representative images of false positive (FP) and false negative (FN) cases.
These images are from six children (a 22-month-old girl, a 16-month-old boy, a 24-month-old boy, a 19-month-old boy, a 17-month-old girl, and a 19-month-old boy, corresponding to A-F, respectively). A-C. In the FP cases, normal bowel (A) or kidney (B) were erroneously identified as ileocolic intussusception. Occasionally, cases in which intussusception was suspected but not labeled due to issues with image quality, such as posterior shadowing, were detected with sensitivity (C). D-F. The FN cases included a variety of transverse and longitudinal images captured using both linear and curved transducers.
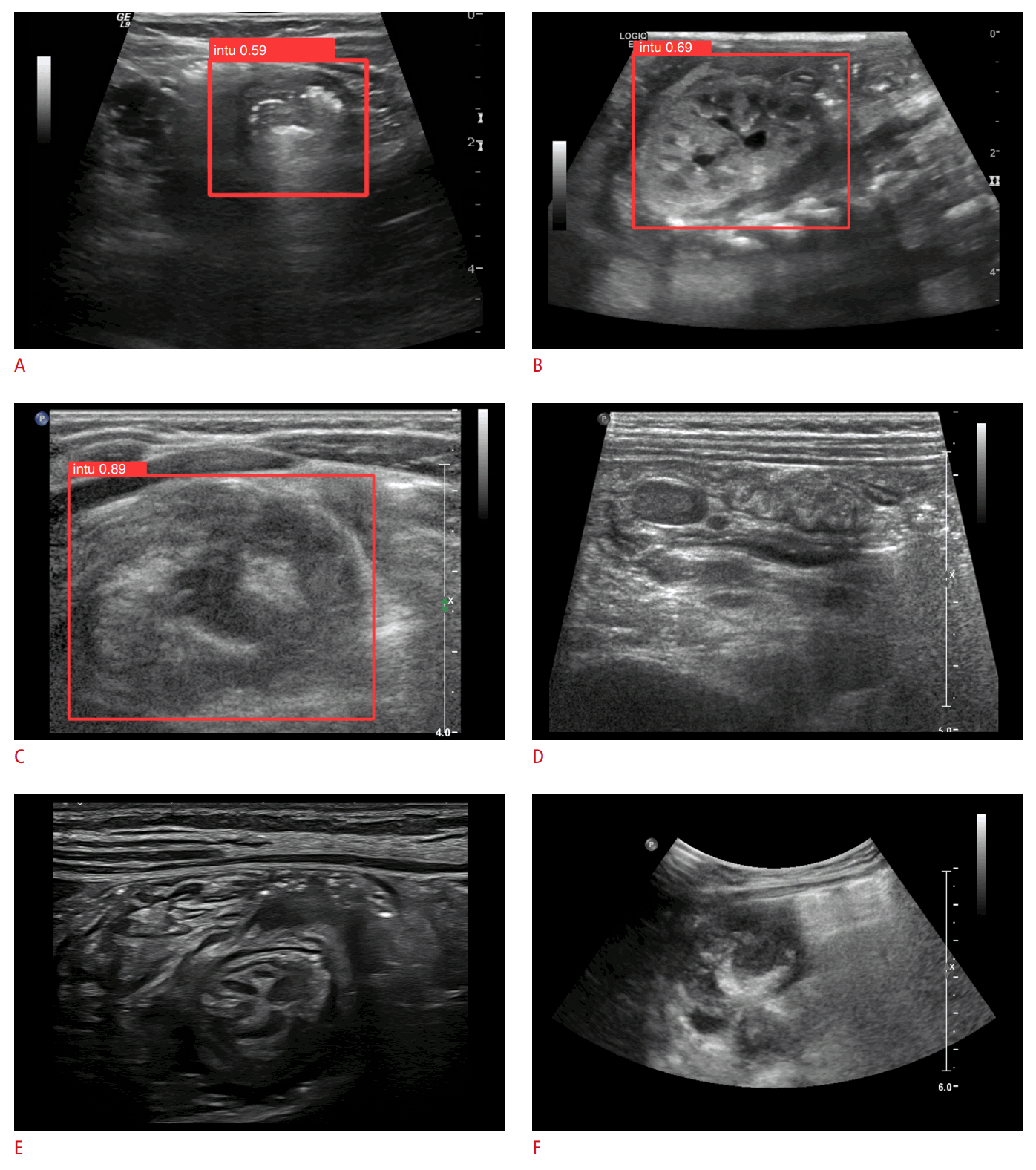
Fig. 5.
Receiver operating characteristic (ROC) curve, free-response ROC (FROC) curve, and alternative free-response ROC (AFROC) curve for the external test set.
A. ROC curve for per-patient diagnosis in the external test set are depicted. B, C. FROC and AFROC curves representing the external test set are depicted. AUROC, area under receiver operating characteristic curve; AUAFROC, area under the alternative free-response receiver operating characteristic curve; CT, confidence threshold; FP, false positive.
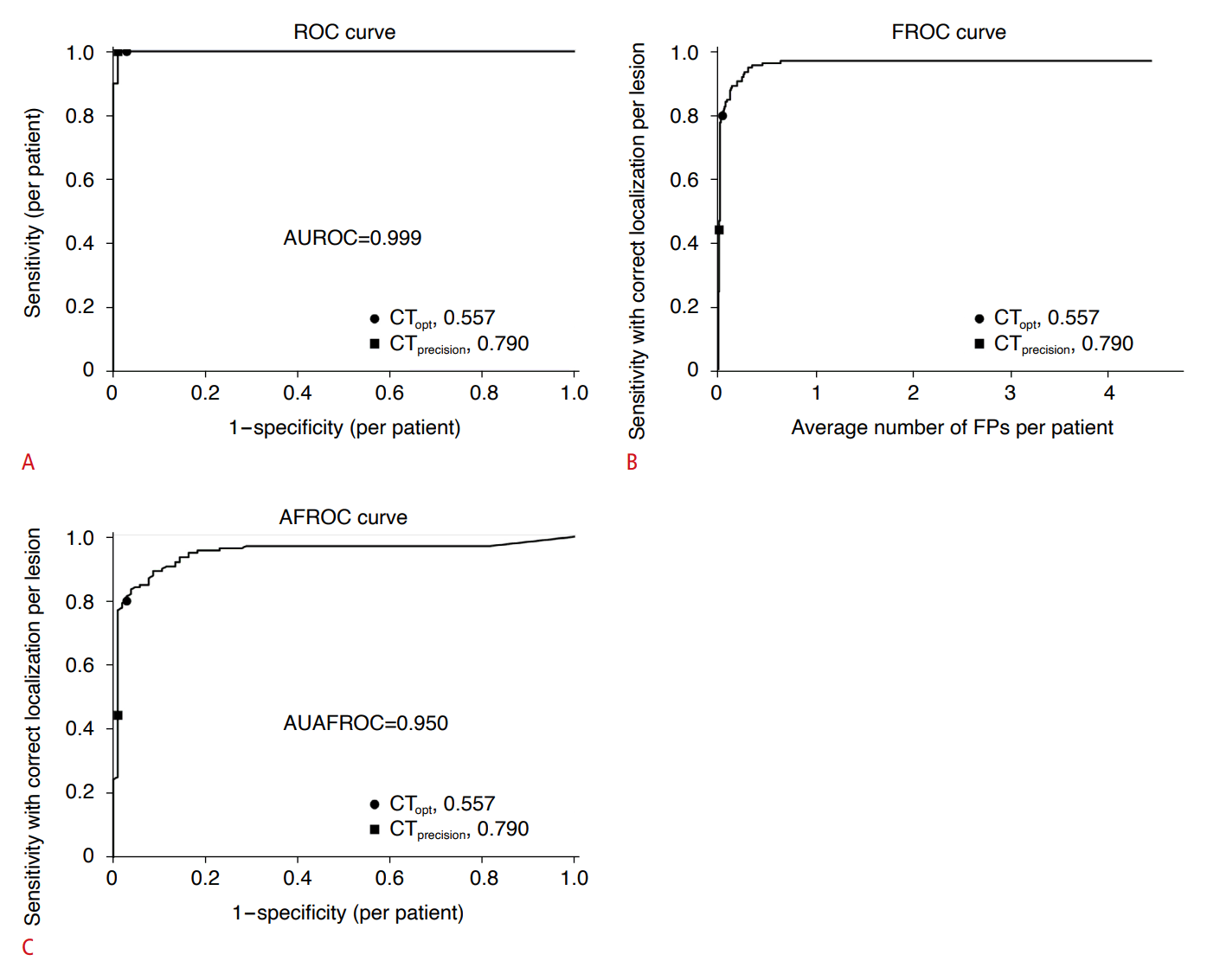

Table 1.
Baseline characteristics of datasets
| Development dataset | External test set | P-value | |
|---|---|---|---|
| No. of patients | 2,438 | 124 | |
| Age (mo)a) | 21.7 (1.4-59.9) | 21.8 (2.2-54.1) | 0.914b) |
| Sex (M:F) | 1,557:881 | 84:40 | 0.380 |
| Diagnosisc) | 26.1 (636/2,438) | 16.1 (20/124) | 0.013 |
| Images | 38,148 | 2,617 | |
| Lesion (+)c) | 7.5 (2,775/37,148) | 5.3 (140/2,617) | <0.001 |
| Cvx:Lin:LinTz | 1,098:846:831 | 56:38:46 | 0.646 |
| Lesion (−)c) | 92.5 (35,373/37,148) | 94.7 (2,477/2,617) | <0.001 |
| Cvx:Lin:LinTz | 12,254:11,471:11,648 | 1,229:644:604 | <0.001 |
Table 2.
Diagnostic performance of deep learning-based model
- REFERENCES
- REFERENCES
References
2. Yang WC, Chen CY, Wu HP. Etiology of non-traumatic acute abdomen in pediatric emergency departments. World J Clin Cases 2013;1:276–284.
[Article] [PubMed] [PMC]3. Edwards EA, Pigg N, Courtier J, Zapala MA, MacKenzie JD, Phelps AS. Intussusception: past, present and future. Pediatr Radiol 2017;47:1101–1108.
[Article] [PubMed]4. McDermott VG. Childhood intussusception and approaches to treatment: a historical review. Pediatr Radiol 1994;24:153–155.
[Article] [PubMed]5. Applegate KE. Intussusception in children: evidence-based diagnosis and treatment. Pediatr Radiol 2009;39 Suppl 2:S140–S143.
[Article] [PubMed]6. Hryhorczuk AL, Strouse PJ. Validation of US as a first-line diagnostic test for assessment of pediatric ileocolic intussusception. Pediatr Radiol 2009;39:1075–1079.
[Article] [PubMed]7. Plut D, Phillips GS, Johnston PR, Lee EY. Practical imaging strategies for intussusception in children. AJR Am J Roentgenol 2020;215:1449–1463.
[Article] [PubMed]8. Kolar M, Pilkington M, Winthrop A, Theivendram A, Lajkosz K, Brogly SB. Diagnosis and treatment of childhood intussusception from 1997 to 2016: a population-based study. J Pediatr Surg 2020;55:1562–1569.
[Article] [PubMed]9. Ekenze SO, Mgbor SO. Childhood intussusception: the implications of delayed presentation. Afr J Paediatr Surg 2011;8:15–18.
[Article] [PubMed]10. Pandey A, Singh S, Wakhlu A, Rawat JJ. Delayed presentation of intussusception in children: a surgical audit. Ann Pediatr Surg 2011;7:130–132.
[Article]11. Fallon SC, Lopez ME, Zhang W, Brandt ML, Wesson DE, Lee TC, et al. Risk factors for surgery in pediatric intussusception in the era of pneumatic reduction. J Pediatr Surg 2013;48:1032–1036.
[Article] [PubMed]12. Blackwood BP, Theodorou CM, Hebal F, Hunter MC. Pediatric intussusception: decreased surgical risk with timely transfer to a children's hospital. Pediatr Care (Wilmington) 2016;2:18.
[Article] [PubMed] [PMC]13. Akello VV, Cheung M, Kurigamba G, Semakula D, Healy JM, Grabski D, et al. Pediatric intussusception in Uganda: differences in management and outcomes with high-income countries. J Pediatr Surg 2020;55:530–534.
[Article] [PubMed]14. Riera A, Hsiao AL, Langhan ML, Goodman TR, Chen L. Diagnosis of intussusception by physician novice sonographers in the emergency department. Ann Emerg Med 2012;60:264–268.
[Article] [PubMed] [PMC]15. van Wassenaer EA, Daams JG, Benninga MA, Rosendahl K, Koot BGP, Stafrace S, et al. Non-radiologist-performed abdominal point-of-care ultrasonography in paediatrics: a scoping review. Pediatr Radiol 2021;51:1386–1399.
[Article] [PubMed] [PMC]16. Tsou PY, Wang YH, Ma YK, Deanehan JK, Gillon J, Chou EH, et al. Accuracy of point-of-care ultrasound and radiology-performed ultrasound for intussusception: a systematic review and meta-analysis. Am J Emerg Med 2019;37:1760–1769.
[Article] [PubMed]17. Bergmann KR, Arroyo AC, Tessaro MO, Nielson J, Whitcomb V, Madhok M, et al. Diagnostic accuracy of point-of-care ultrasound for intussusception: a multicenter, noninferiority study of paired diagnostic tests. Ann Emerg Med 2021;78:606–615.
[Article] [PubMed]18. Tonson la Tour A, Desjardins MP, Gravel J. Evaluation of bedside sonography performed by emergency physicians to detect intussusception in children in the emergency department. Acad Emerg Med 2021;28:866–872.
[Article] [PubMed]19. Kim S, Yoon H, Lee MJ, Kim MJ, Han K, Yoon JK, et al. Performance of deep learning-based algorithm for detection of ileocolic intussusception on abdominal radiographs of young children. Sci Rep 2019;9:19420.
[Article] [PubMed] [PMC]20. Kwon G, Ryu J, Oh J, Lim J, Kang BK, Ahn C, et al. Deep learning algorithms for detecting and visualising intussusception on plain abdominal radiography in children: a retrospective multicenter study. Sci Rep 2020;10:17582.
[Article] [PubMed] [PMC]21. Kim YH. Artificial intelligence in medical ultrasonography: driving on an unpaved road. Ultrasonography 2021;40:313–317.
[Article] [PubMed] [PMC]22. Song KD. Current status of deep learning applications in abdominal ultrasonography. Ultrasonography 2021;40:177–182.
[Article] [PubMed]23. Wada K, Kubovcik M, Myczko A, Zhu L, Yamaguchi N, Fujii S, et al. Labelme: Image Polygonal Annotation with Python [Internet]. Geneva: Zenodo, 2021. [cited 2023 Aug 7]. Available from: https://doi.org/10.5281/zenodo.5711226.
[Article]24. Russell BC, Torralba A, Murphy KP, Freeman WT. LabelMe: a database and web-based tool for image annotation. Int J Compout Vis 2008;77:157–173.
[Article]25. Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016 Jun 27-30; Las Vegas, NV, USA. Piscataway, NJ: Institute of Electrical and Electronics Engineers, 2016. 779–788.
[Article]26. Jocher G, Chaurasia A, Stoken A, Boroec J, Kwon Y, Xie T, et al. YOLOv5 by Ultralytics (version 6.1) [Internet]. Geneva: Zenodo, 2022. [cited 2023 Aug 7]. Available from: https://doi.org/10.5281/zenodo.6222936.
[Article]27. Zou Z, Chen K, Shi Z, Guo Y, Ye J. Object detection in 20 years: a survey. Proc IEEE 2023;111:257–276.
[Article]28. Padilla R, Netto SL, Da Silva EA. A survey on performance metrics for object-detection algorithms. 2020 International Conference on Systems, Signals and Image Processing (IWSSIP); 2020 Jul 1-3; Niteroi, Brazil. Piscataway, NJ: Institute of Electrical and Electronics Engineers, 2020. 237–242.
[Article]29. Ying X. An overview of overfitting and its solutions. J Phys Conf Ser 2019;1168:022022.
[Article]